Zusammenfassung:
In der letzten Stunde haben wir die Stoffklasse der Proteine kennengelernt. Neben den Kohlenhydraten, die dem Organismus die nötige Energie liefern, und den Fetten, die als Energiespeicher dienen und an Transportprozessen beteiligt sind, sind die Proteine essentiell für den Aufbau des Organismus und stellen mit den Enzymen die wichtigste Stoffgruppe biologisch aktiver Makromoleküle dar. Proteine sind aus Aminosäuren aufgebaut, die durch die sogenannte Peptidbindung zu langen Polypeptidketten verknüpft werden. Innerhalb dieser Primärstruktur bilden sich aufgrund sogenannter Wasserstoffbrücken Sekündärstrukturen aus. Hierbei unterscheidet man zwischen Alpha Helices und ß-Falltblattstrukturen. Solche Sekündärstrukturen können sich dann zu komplexeren Tertiärstrukturen (zB. ß-Fass) zusammenschliessen. Wenn sich mehrere Untereinheiten zu einem Protein zusammenschliessen spricht man schliesslich von der Quartiärstruktur.
 |
| Quelle: Richard Wheeler (Zephyris) at en.wikipedia |
Der Bauplan aller in unserem Körper vorkommenden Proteine wird von einer weiteren Molekülklasse codiert, der DNA. DNA steht für Deoxyribonucleinsäure, auf englisch deoxyribonucleic acid (DNA). Jedes Protein wird dabei von einem Gen codiert. Man spricht in diesem Zusammenhang auch von der "Ein Gen-ein Polypeptid" Hypothese.
Um zu verstehen, wie man in einem einzigen Molekül die Baupläne tausender Proteine speichern kann, muss man verstehen wie die DNA aufgebaut ist:
Folgende Videos beschreiben die Zusammenhänge in anschaulicher Form:
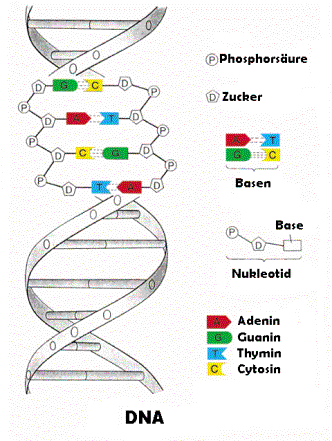
Der Aufbau der DNA ähnelt einer in sich verdrehten Leiter. Man spricht
auch von der Doppelhelix der DNA, da sie aus zwei DNA Strängen besteht,
die ineinander verdreht sind.
Hauptbestandteile der DNA sind die
sogenannten Nukleinsäuren, lange Kettenmoleküle (Polymer) die aus vier
verschiedenen Bausteinen, den Nukleotiden aufgebaut sind. Jedes
Nukleotid besteht aus einem Phosphat-Rest, dem Zucker Desoxyribose und
einer von vier organischen Basen (Adenin, Thymin, Guanin und Cytosin,
oft abgekürzt mit A, T, G und C). Adenin paart sich dabei über 2 Wasserstoffbrücken mit dem Thymin, wohingegen Guanin sich über 3 Wasserstoffbrücken mit Cytosin paart. A und T, sowie G und C bilden jeweils ein sogenanntes Basenpaar.
 |
| Quelle: http://www.tgg-leer.de/projekte/genetik/dna2/dna2.html |
Die Großteil der DNA ist bei mehrzelligen Organismen (Eukaryonten) im Zellkern organisiert. Daneben ist ein kleinerer Teil der DNA (die mitochondriale DNA) in den Mitochondrien gespeichert. In Pflanzen und Algen ist daneben ein weiterer Teil auch in den Chloroplasten, den Photosynthese betreibenden Organellen, gespeichert.
Würde man die DNA, die im Zellkern jeder menschlichen Zelle gespeichert ist, ausbreiten, wäre die DNA ca 1,80 m lang.
Damit dieser 1,80 m lange Faden in den Zellkern einer menschlichen Zelle passt (Durchmesser 5-16 µm!), ist die DNA vielfach ineinander verdreht und auf sogenannte Histone gespult, die wiederum in Form einer Perlenschnur organisiert sind. Die folgende Abbildung gibt euch einen Überblick über die Organisation der DNA:
 |
| By Courtesy: National Human Genome Research Institute. |
1990 wurde das Humane Genomprojekt ins Leben gerufen, mit dem Ziel den menschlichen Code vollständig zu entschüsseln. 1998 bekam dieses staatenübergreifende Forschungsprojekt private Konkurrenz durch die neu gegründete Firma Celera und deren Gründer Craig Venter. Dieser Konkurrenzkampf beschleunigte die Entschlüsselung des menschlichen Codes ungemein. 2003 wurde das menschliche Genom schliesslich als entschlüsselt bekanntgegeben.
Der Ausdruck "entschlüsselt" ist jedoch nicht ganz richtig. Zwar ist die Abfolge der Nukleotide A, T, C und G in der menschlichen DNA jetzt bekannt, doch wofür die unterschiedlichen Bereiche des Genoms codieren ist zu einem großen Teil noch völlig unverstanden. Den menschlichen, genetischen Code zu verstehen ist Ziel eines neuen Projektes, des ENCODE Projektes:
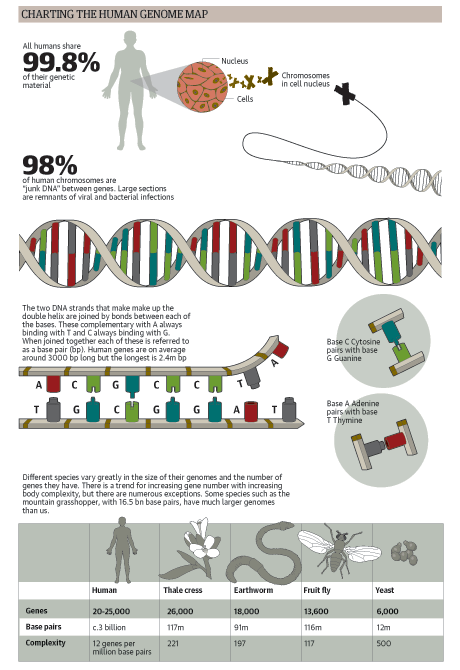
Die folgende Abbildung fast einige Fakten zur menschlichen DNA zusammen:
 |
| Quelle: www.theguardian.com |
Das menschliche Genom besteht also aus ca 3 Milliarden Basenpaaren. Diese codieren für ca 20000-25000 Gene (Proteine). 98% der DNA codieren nicht für Gene und werden als nicht-codierende Bereiche (Introns) bezeichnet. Diese sind zum einen Überbleibsel von bakterieller und viraler DNA, die sich zum Beispiel aufgrund einer Infektion in das menschliche Genom eingebaut haben, stellen zum Teil jedoch auch regulatorische Elemente dar, die man jetzt erst anfängt zumindest teilweise zu verstehen. So verschieden wir Menschen auch sind, sind 98,8% unserer DNA vollkommen identisch.
Chromosomen
Die DNA des Menschen liegt nicht als ein einziger durchgängiger DNA Faden im Zellkern vor, sondern ist auf sogenannte Chromosomen aufgeteilt. Nicht alle Lebewesen haben gleich viele Chromosomen: Der Mensch hat im Ganzen 46 Chromosomen, wobei 23 Chromosomen von der Mutter und 23 Chromosomen vom Vater stammen. Folgende Abbildung zeigt das Karyogramm eines Mannes.
Bezüglich des Chromosomenbegriffes kommt es sehr oft zu Mißverständnissen, die darauf beruhen, dass auch nicht verdoppelte Chromatiden als Chromosom bezeichnet werden.
Folgendes Video erklärt die richtigen Zusammenhänge in anschaulicher Form:
Chromosomen
 |
| Chromosom (Quelle: Magnus Manske, User:Dietzel65 (Nupedia, then en.wikipedia) via Wikimedia Commons) |
Chromosomen
Die DNA des Menschen liegt nicht als ein einziger durchgängiger DNA Faden im Zellkern vor, sondern ist auf sogenannte Chromosomen aufgeteilt. Nicht alle Lebewesen haben gleich viele Chromosomen: Der Mensch hat im Ganzen 46 Chromosomen, wobei 23 Chromosomen von der Mutter und 23 Chromosomen vom Vater stammen. Folgende Abbildung zeigt das Karyogramm eines Mannes.
 |
| Karyogramm eines Mannes (Quelle: Wikipedia.commons) |
Folgendes Video erklärt die richtigen Zusammenhänge in anschaulicher Form:
Chromosomen
Wie funktioniert der gentische Code ?
Wir haben in der vorherigen Stunde gelernt, dass Proteine aus 20 verschiedenen, natürlichen Aminosäuren aufgebaut sein können.
Für die Codierung dieser 20 natürlichen Aminosäuren stehen auf DNA Ebene jedoch nur 4 unterschiedliche Nukleotide zur Verfügung (Adenin, Thymin, Cytosin und Guanin). Damit also 20 verschiedene Aminosäuren codiert werden können, muss eine Aminosäure jeweils durch die Abfolge von 3 Nukleotiden definiert sein. Man bezeichnet solch eine Abfolge von 3 Nukleotiden als sogenanntes Basentriplett oder auch Codon.
Die folgende Übersicht zeigt euch den genetischen Code.
Zum jetzigen Zeitpunkt reicht es aus, wenn Ihr wisst, dass die Base Thymin (T) in dieser Abbildung durch ein U dargestellt ist. Wir werden in einem der späteren Kapitel wieder hierauf zurückkommen.
Wir haben in der vorherigen Stunde gelernt, dass Proteine aus 20 verschiedenen, natürlichen Aminosäuren aufgebaut sein können.
Für die Codierung dieser 20 natürlichen Aminosäuren stehen auf DNA Ebene jedoch nur 4 unterschiedliche Nukleotide zur Verfügung (Adenin, Thymin, Cytosin und Guanin). Damit also 20 verschiedene Aminosäuren codiert werden können, muss eine Aminosäure jeweils durch die Abfolge von 3 Nukleotiden definiert sein. Man bezeichnet solch eine Abfolge von 3 Nukleotiden als sogenanntes Basentriplett oder auch Codon.
Die folgende Übersicht zeigt euch den genetischen Code.
Zum jetzigen Zeitpunkt reicht es aus, wenn Ihr wisst, dass die Base Thymin (T) in dieser Abbildung durch ein U dargestellt ist. Wir werden in einem der späteren Kapitel wieder hierauf zurückkommen.
 |
| Der genetische Code |
Dieser genetische Code ist in allen Organismen gültig. Es fällt auf, dass dieser Code redundant ist, d.h. mehrere Codons codieren für die gleiche Aminosäure. 4 Codons haben des weiteren eine besondere Funktion: Sie legen in der komplexen DNA Sequenz den Start bzw. das Ende eines Gens fest. Das Codon ATG wird als sogenanntes Startcodon bezeichnet. Es ist in Eukaryoten das einzige Startcodon, das den Start eines jeden Gens definiert und für die Aminosäure Methionin codiert. Bei der Verwendung dieses Startcodons beginnt also jedes Protein mit einem Methionin. Dieses Methionin bleibt jedoch bei einem Teil der entstehenden Proteine nicht erhalten, sondern wird später abgespalten. Auch hierauf werden wir an entsprechender Stelle wieder zurückkommen. Bei Prokaryoten gibt es alternativ ein zweites Startcodon, GTG, das jedoch sehr selten zum Einsatz kommt, und im Gegensatz zum ATG Codon für keine Aminosäure codiert.
Die Stoppcodons TAA, TAG und TGA markieren hingegen das Ende eines Gens. Sie codieren für keine spezielle Aminosäure, sondern übermitteln der Proteinmachinerie lediglich, dass das Protein fertig ist.
Keine Kommentare:
Kommentar veröffentlichen